Amazon S3
- 07 Oct 2025
- 2 Minutes to read
- Print
- DarkLight
Amazon S3
- Updated on 07 Oct 2025
- 2 Minutes to read
- Print
- DarkLight
Article summary
Did you find this summary helpful?
Thank you for your feedback!
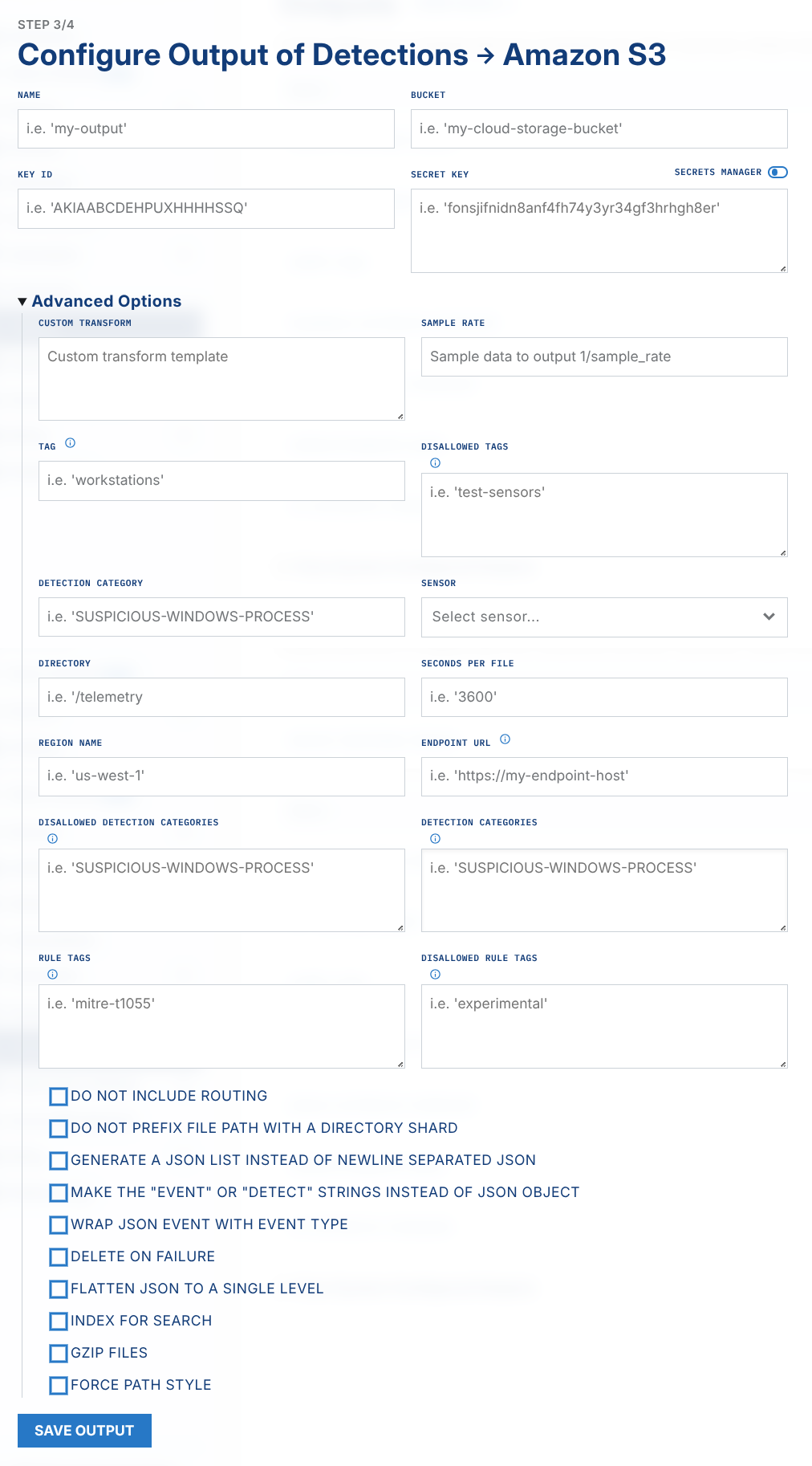
Output events and detections to an Amazon S3 bucket.
If you have your own visualization stack, or you just need the data archived, you can output directly to Amazon S3. This way you don't need any infrastructure.
bucket: the path to the AWS S3 bucket.key_id: the id of the AWS auth key.secret_key: the AWS secret key to auth with.sec_per_file: the number of seconds after which a file is cut and uploaded.is_compression: if set to "true", data will be gzipped before upload.is_indexing: DEPRECATED if set to "true", data is uploaded in a way that makes it searchable.region_name: the region name of the bucket, it is recommended to set it, though not always required.endpoint_url: optionally specify a custom endpoint URL, usually used with region_name to output to S3-compatible 3rd party services.dir: the directory prefixis_no_sharding: do not add a shard directory at the root of the files generated.
Example:
bucket: my-bucket-name
key_id: AKIAABCDEHPUXHHHHSSQ
secret_key: fonsjifnidn8anf4fh74y3yr34gf3hrhgh8er
is_indexing: "true"
is_compression: "true"
If the is_indexing option is enabled, data uploaded to S3 will be in a specific format enabling some indexed queries.
LC data files begin with a d, while special manifest files (indicating
which data files contain which sensors' data) begin with an m. Otherwise (not is_indexing), data is uploaded as flat files with a UUID name.
The is_compression flag, if on, will compress each file as a GZIP when uploaded. It is recommended you enable is_compression.
AWS IAM Configuration
Log in to AWS console and go to the IAM service.
Click on
Usersfrom the menu.Click
Create User, give it a name, and clickNext.Click
Next, thenCreate UserClick on the user you just created and click on the
Security CredentialstabClick
Create access keySelect
Otherand clickNextProvide a description (optional) and click
Create access keyTake note of the "Access key", "Secret access key" and ARN name for the user (starts with "arn:", shown on the user summary screen).
AWS S3 Configuration
Go to the S3 service.
Click
Create bucket, enter a name and select a region.Click
Create bucketClick on your newly created bucket and click on the
PermissionstabSelect
Bucket policyand clickEditInput the policy in sample below where you replace the
<<USER_ARN>>with the ARN name of the user you created and the<<BUCKET_NAME>>with the name of the bucket you just created.Click
Save Changes
Policy Sample
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "PermissionForObjectOperations",
"Effect": "Allow",
"Principal": {
"AWS": "<<USER_ARN>>"
},
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::<<BUCKET_NAME>>/*"
}
]
}
LimaCharlie Configuration
Back in the LimaCharlie GUI, in your organization view, click
OutputsandAdd OutputSelect the stream you would like to send (events, detections, etc)
Select the
Amazon S3destinationGive it a name, enter the bucket name, key_id, and secret_key you noted from AWS, and any other parameters you wish to configure
Click
Save OutputAfter a minute, the data should start getting written to your bucket
Was this article helpful?