Velociraptor to BigQuery
- 08 Oct 2025
- 3 Minutes to read
- Print
- DarkLight
Velociraptor to BigQuery
- Updated on 08 Oct 2025
- 3 Minutes to read
- Print
- DarkLight
Article summary
Did you find this summary helpful?
Thank you for your feedback!
Overview
Our BigQuery output allows you to send Velociraptor hunt results to a BigQuery table allowing SQL-like queries against the hunt data. This is very similar to using Velociraptor notebooks, allowing you to perform hunt analysis at scale against massive datasets. For guidance on using LimaCharlie to execute Velociraptor hunts, see Velociraptor Extension.
Imagine you wanted to obtain running processes from 10s, 100s, or 1000s of systems using Velociraptor. You could easily issue a Windows.System.Pslist hunt across these systems, and let LimaCharlie push Velociraptor to the endpoints and collect the results. The issue is, if you want to run queries against all of the data returned by the hunts, you'll need a database-like tool to do that which is where BigQuery comes in.
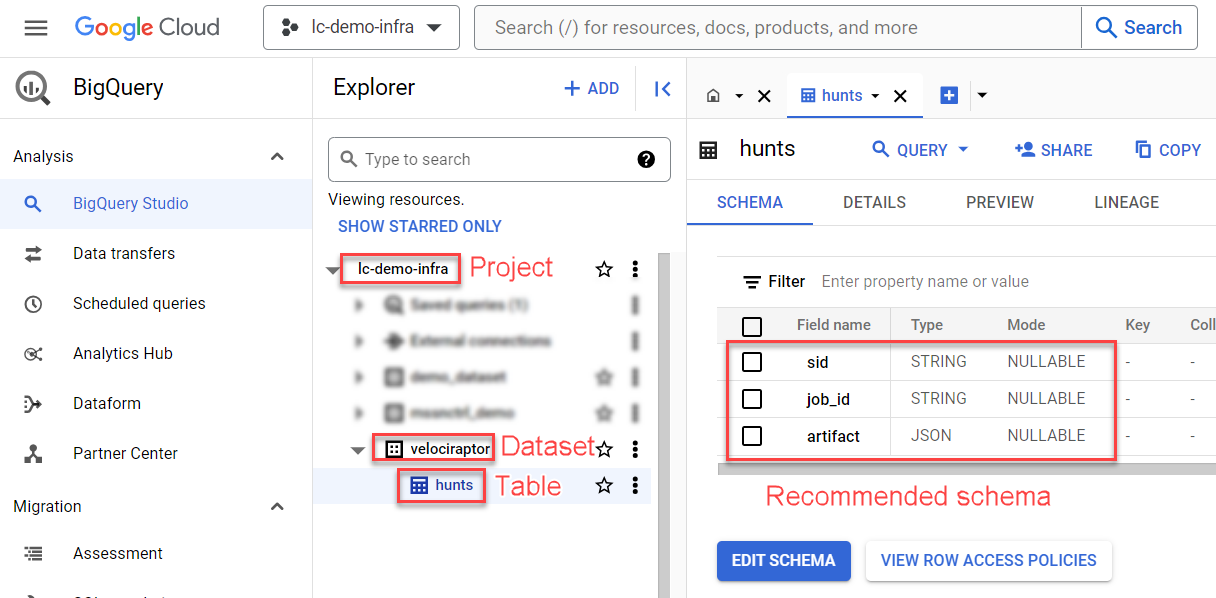
BigQuery dataset containing Velociraptor hunt results: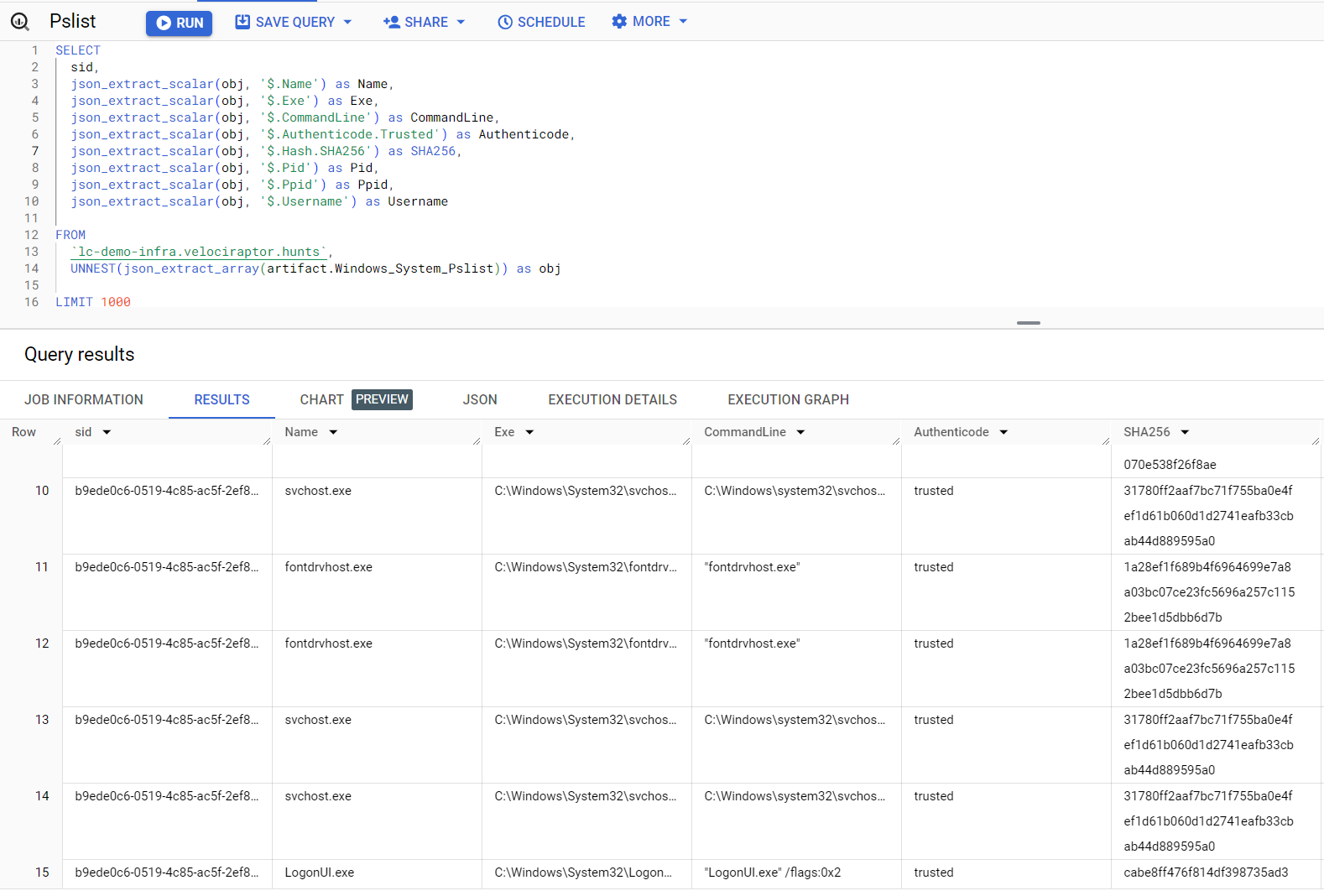
Steps to Accomplish
You will need a Google Cloud project
You will need to create a service account within your Google Cloud project
Navigate to your project
Navigate to IAM
Navigate to Service Accounts > Create Service Account
Click on newly created Service Account and create a new key
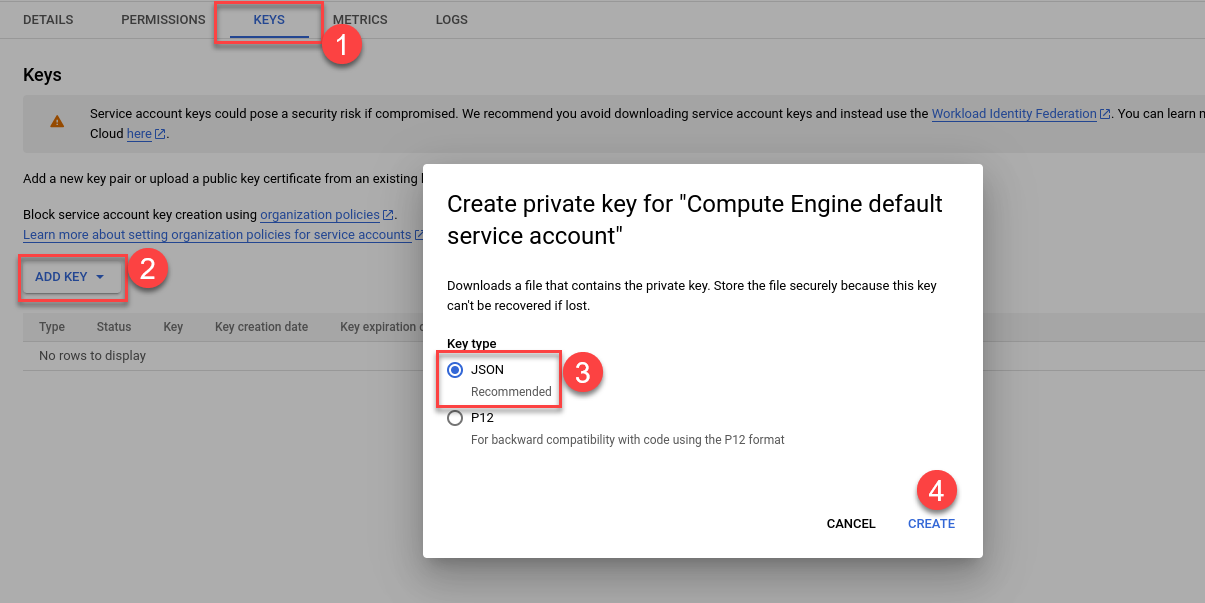
This will provide you with the JSON format secret key you will later setup in your LimaCharlie output
In BigQuery, create a Dataset, Table, & Schema similar to the screenshot below
Now we're ready to create our LimaCharlie tailored output
In the side navigation menu, click "Outputs" then add a new output
Output stream: Tailored
Destination: Google Cloud BigQuery
Name:
bigquery-tailoredYou can change this, but it affects a subsequent step so take note of the output name
schema:
sid:STRING, job_id:STRING, artifact:JSONDataset: whatever you named BQ your dataset above
Table: whatever you named your BQ table above
Project: your GCP project name
Secret Key: provide the JSON secret key for your GCP service account
Advanced Options
Custom Transform: paste in this JSON
{ "sid": "event.sid", "job_id": "event.job_id", "artifact": "{{ json .event.collection }}" }Specific Event Types:
velociraptor_collection
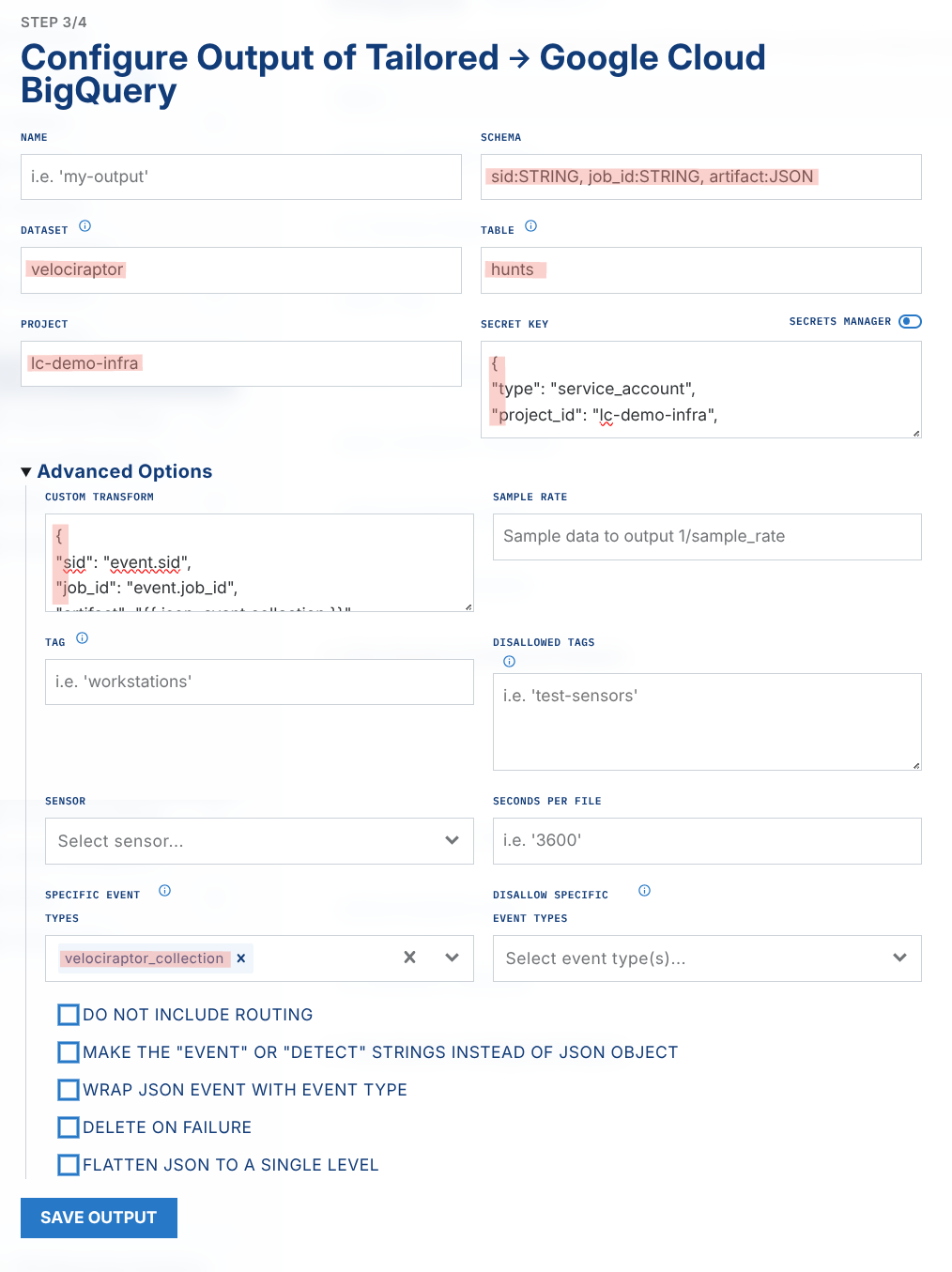
We now need a rule that will watch for Velociraptor collections send send them to the new tailored output
Create a new D&R rule
Detection
event: velociraptor_collection op: exists path: event/collectionResponse
- action: output name: bigquery-tailored # must match the output name you created earlier - action: report name: Velociraptor hunt sent to BigQuery
You are now ready to send Velociraptor hunts to BigQuery!
BigQuery Tips
Query Examples
Once the data arrives in BigQuery, it will be in three simple columns: sid, job_id, and artifact. The artifact column contains the raw JSON of the hunt results from each sensor that returned results.

Let's say we wanted to split out all results of a Windows.System.Pslist hunt so that each process, from each system, is returned in it's own row. Here is an example notebook to accomplish this:
SELECT
sid,
json_extract_scalar(obj, '$.Name') as Name,
json_extract_scalar(obj, '$.Exe') as Exe,
json_extract_scalar(obj, '$.CommandLine') as CommandLine,
json_extract_scalar(obj, '$.Authenticode.Trusted') as Authenticode,
json_extract_scalar(obj, '$.Hash.SHA256') as SHA256,
json_extract_scalar(obj, '$.Pid') as Pid,
json_extract_scalar(obj, '$.Ppid') as Ppid,
json_extract_scalar(obj, '$.Username') as Username
FROM
`lc-demo-infra.velociraptor.hunts`,
UNNEST(json_extract_array(artifact.Windows_System_Pslist)) as obj
LIMIT 1000
Be sure to swap out lc-demo-infra.velociraptor.hunts for your own project.dataset.table names.
This results in the following view of our data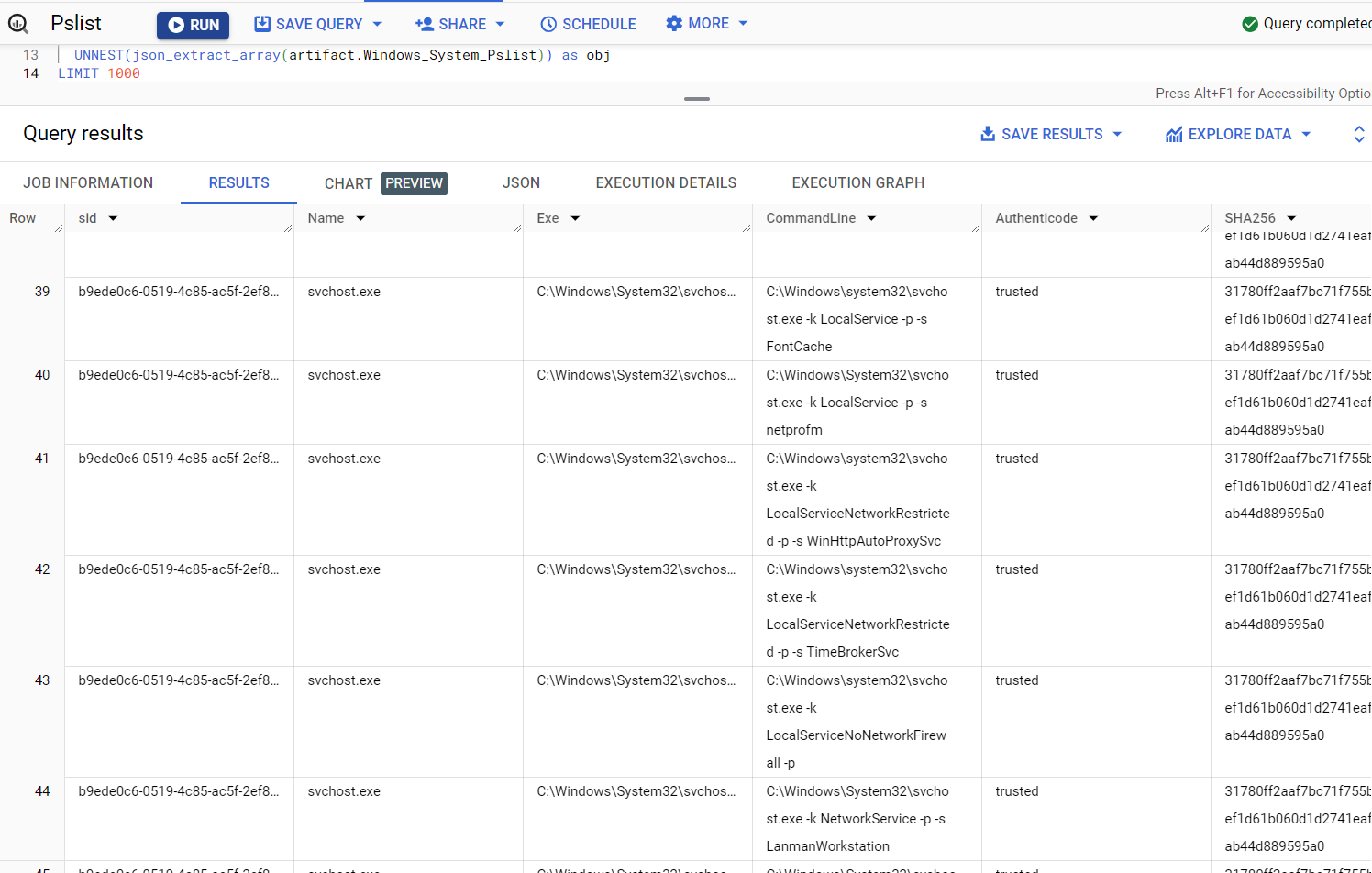
Suppose we wanted to perform some stacking analysis to identify the rarest combinations of Exe and CommandLine; the following query could help:
SELECT
json_extract_scalar(obj, '$.Exe') as Exe,
json_extract_scalar(obj, '$.CommandLine') as CommandLine,
COUNT(*) as Count
FROM
`lc-demo-infra.velociraptor.hunts`,
UNNEST(json_extract_array(artifact.Windows_System_Pslist)) as obj
GROUP BY
Exe,
CommandLine
ORDER BY
Count ASC
This results in the following view of our data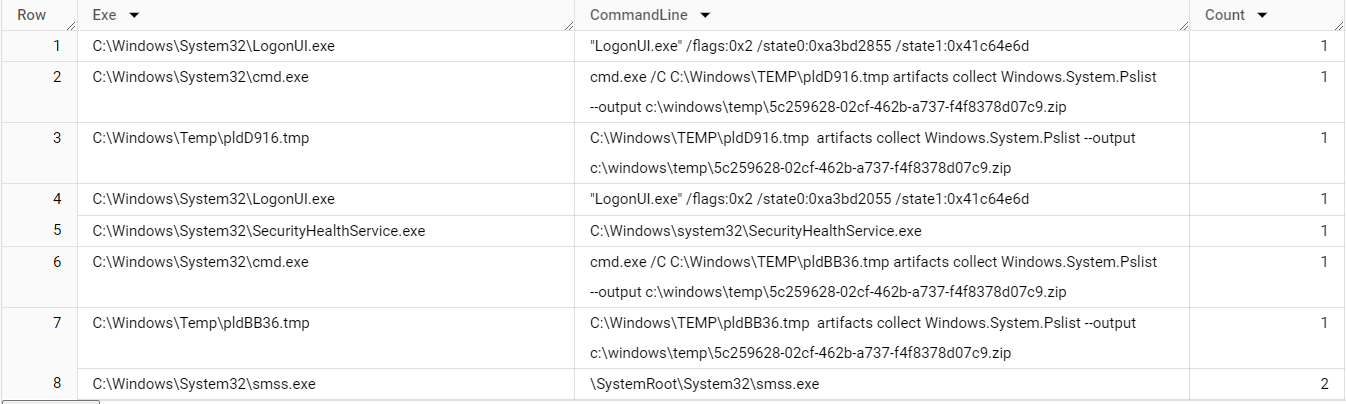
Now let's say you wanted to look for only processes that are Authenticode = untrusted, you would use a query such as this:
SELECT
sid,
json_extract_scalar(obj, '$.Name') as Name,
json_extract_scalar(obj, '$.Exe') as Exe,
json_extract_scalar(obj, '$.CommandLine') as CommandLine,
json_extract_scalar(obj, '$.Authenticode.Trusted') as Authenticode,
json_extract_scalar(obj, '$.Hash.SHA256') as SHA256,
json_extract_scalar(obj, '$.Pid') as Pid,
json_extract_scalar(obj, '$.Ppid') as Ppid,
json_extract_scalar(obj, '$.Username') as Username
FROM
`lc-demo-infra.velociraptor.hunts`,
UNNEST(json_extract_array(artifact.Windows_System_Pslist)) as obj
WHERE
json_extract_scalar(obj, '$.Authenticode.Trusted') = 'untrusted'
LIMIT 1000
WHERE Filters for Specific Conditions
Here are some brief examples of WHERE statements to perform specific filtering.
String presence
This example checks for the presence of a string mimikatz appearing anywhere within CommandLine
WHERE
STRPOS(json_extract_scalar(obj, '$.CommandLine'), 'mimikatz') > 0 AND
Compare integers
This example checks for the presence of an integer 0 in a numeric field GroupID
WHERE
CAST(json_extract_scalar(obj, '$.GroupID') AS INT64) = 0
Parsing Nested JSON Objects
In the Windows.System.Pslist examples above, there are a few columns which contain nested JSON such as Authenticode and Hash. To expand these objects in their entirety in the corresponding column/row, we'd write a query like this:
SELECT
json_extract(obj, '$.Authenticode') as Authenticode, # json_extract to unpack nested json
json_extract_scalar(obj, '$.Authenticode.Trusted') as Trusted,
json_extract(obj, '$.Hash') as Hashes, # json_extract to unpack nested json
json_extract_scalar(obj, '$.Hash.SHA256') as SHA256, # extract a specific field from the nested json
FROM
`lc-demo-infra.velociraptor.hunts`,
UNNEST(json_extract_array(artifact.Windows_System_Pslist)) as obj
LIMIT 1000
See the output of this query below: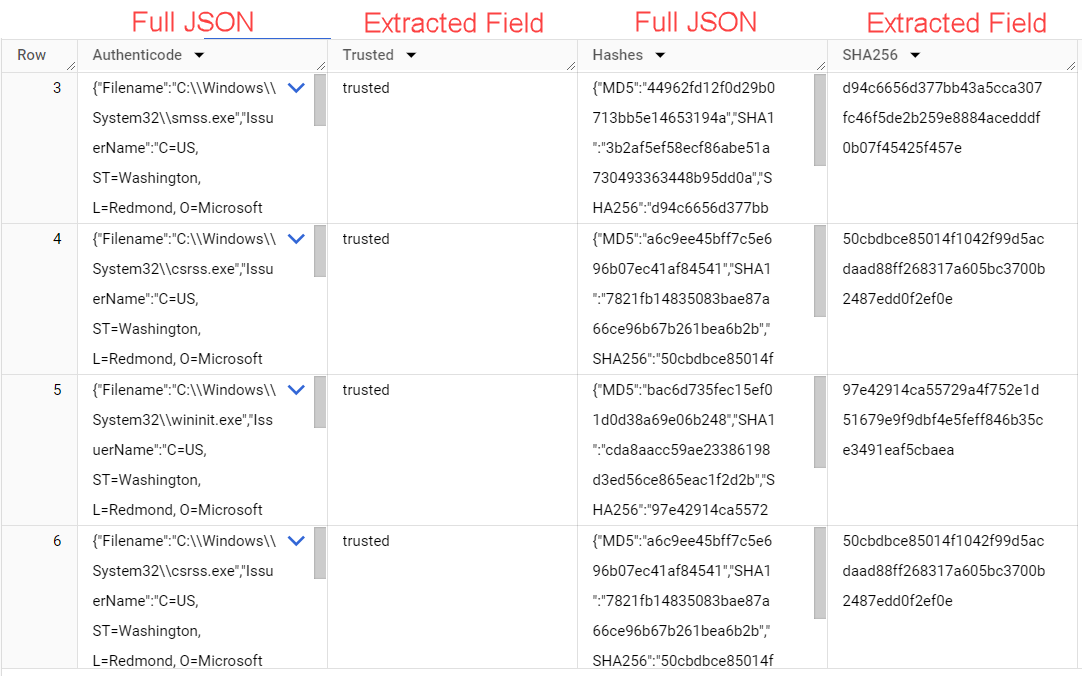
Was this article helpful?